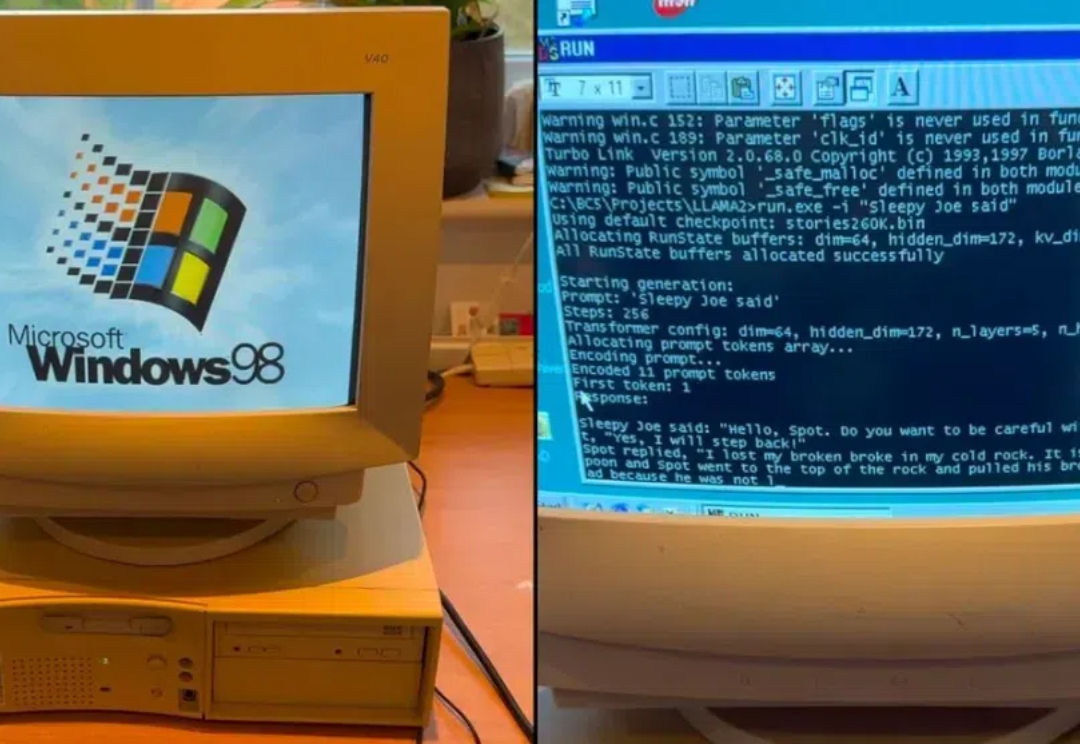
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。
来自主题: AI资讯
9726 点击 2024-12-30 15:15
 搜索
搜索
让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。

Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能,据称在某些基准下能超越Llama 2 70B。

2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。
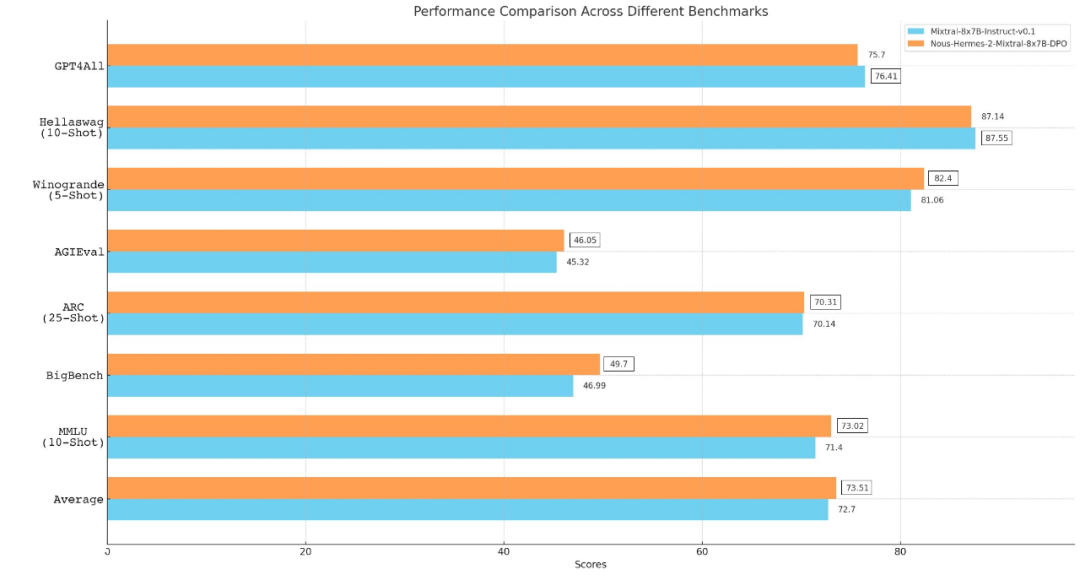
从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。

爆火社区的Mixtral 8x7B模型,今天终于放出了arXiv论文!所有模型细节全部公开了。

都快到年底了,大模型领域还在卷,今天,Microsoft发布了参数量为2.7B的Phi-2——不仅13B参数以内没有对手,甚至还能和Llama 70B掰手腕!

一条神秘磁力链接引爆整个AI圈,现在,正式测评结果终于来了:首个开源MoE大模型Mixtral 8x7B,已经达到甚至超越了Llama 2 70B和GPT-3.5的水平。

前几日,一条MoE的磁力链接引爆AI圈。刚刚出炉的基准测试中,8*7B的小模型直接碾压了Llama 2 70B!网友直呼这是初创公司版的超级英雄故事,要赶超GPT-4只是时间问题了。有趣的是,创始人姓氏的首字母恰好组成了「L.L.M.」。